I recently had to solve a problem where we had a very large and heavily used database table that was starting to see some performance issues. The table was around 85 million rows, and growing by about 100,000 rows per day. The table started requiring manual intervention of killing hung queries daily. We were bailing out a sinking ship. It was very clear that something had to be done.
Ultimately, we wanted the ability to keep X number of months of data in the database, and then move older data to a longer term archive. I started looking into the best way to achieve this and stumbled across a Postgres feature called Table Partitioning. This solved our problem perfectly.
The basic gist is that you have parent table that you can send queries to, but the data actually lives in many smaller child tables. You end up with something that looks like this
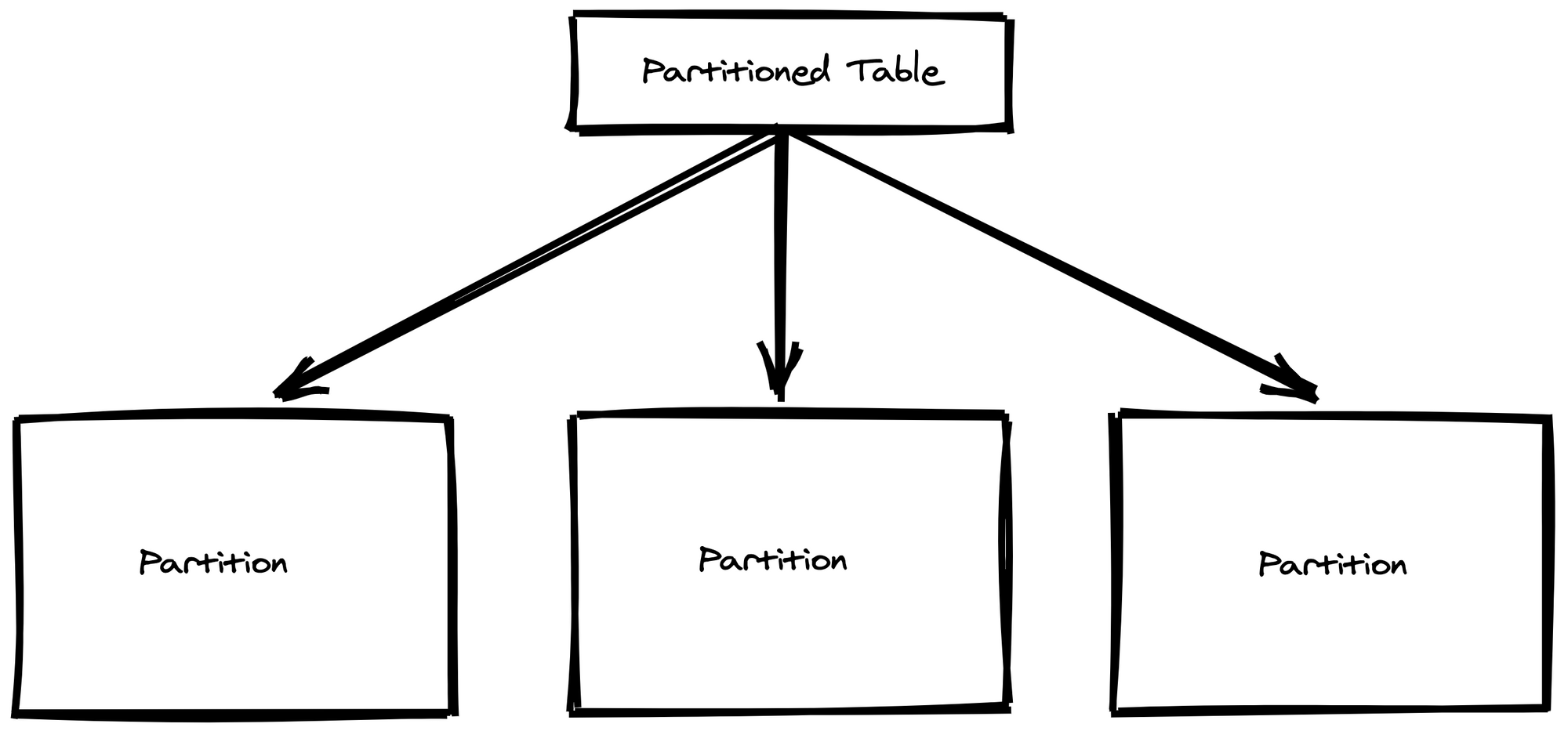
Now, when you want to remove data that's no longer needed you simply drop the child partition that contains the unwanted data. This is much easier and less taxing that performing a delete operation on a large table. The benefits don't end there either. Indexing is setup on the child tables so you can keep the indexes much smaller. Postgres also has a constraint_exclusion setting that defaults to partition. This setting tells the query planner to ignore partitions that could not contain rows that satisfy a query's where clause.
Lets look at an example where we have a very large orders table with a decade of order details in it. 90% of the queries to the table are only interested in orders for the current month, 9% of the queries are interested in orders in the last year, and 1% are interested in all orders. Looking at this break down it seems silly to keep data older than one year if only 1% of the queries are interested in that data.
Instead it would make sense to only keep one year of data on hand in the database, and anything older could live in a data lake somewhere. We also want to optimize for the 90% of queries which are interested in the current month. Let's look at how table partitioning can help here.
We'll start by creating our hypothetical orders table:
CREATE TABLE orders
(
order_id serial,
customer_id integer,
order_total integer,
order_date timestamp with time zone
) PARTITION BY RANGE (order_date)You can see that this looks like a normal CREATE TABLE query. The only difference is the PARTITION BY RANGE (order_date). This defines the partition key which dictates how our data will be partitioned. In our example the table will be partitioned based on the order_date column.
Next we need to create a child partition to hold our data. We're going to keep one month of data in each child table.
CREATE TABLE orders_2020_06 PARTITION OF orders
FOR VALUES FROM ('2020-06-01') TO ('2020-07-01');This looks a little different. The name orders_2020_06 is completely arbitrary, we could have named the table orders_june_2020 or little_bo_peep it really doesn't matter. The PARTITION OF orders statement tells Postgres this is a child partition of the orders table. The FOR VALUES FROM (x) TO (y) statement tells Postgres which values from the partition key will be stored in this table. It's important that there is no potential for overlap between the child tables or you'll run into errors.
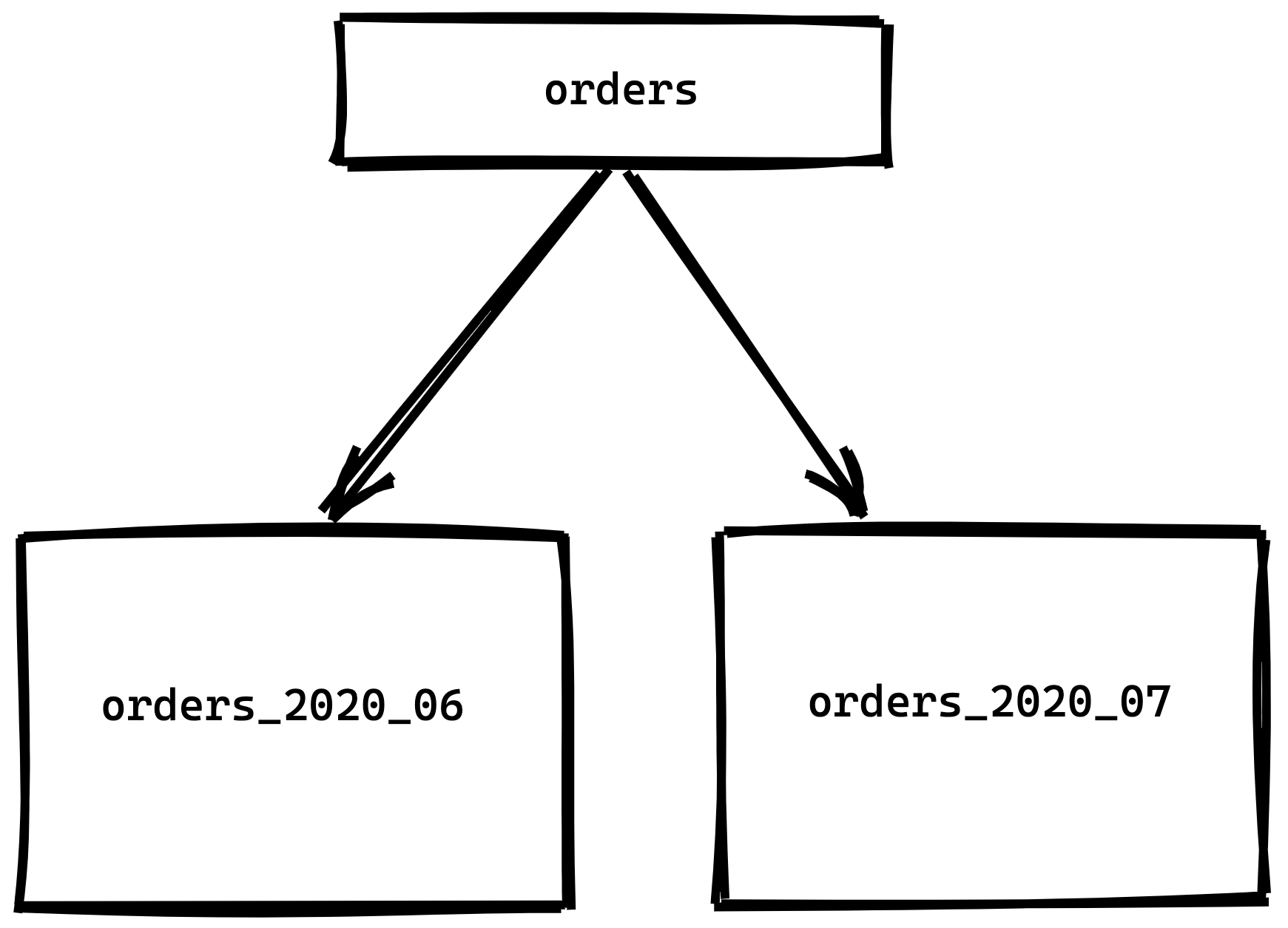
We'll also create a table for next month's data as well
CREATE TABLE orders_2020_07 PARTITION OF orders
FOR VALUES FROM ('2020-07-01') TO ('2020-08-01');Our orders table will now look something like this:
Now when we insert an order it will get stored in the proper child table based on the record's order_date. For example, the following insert statement would get stored in the orders_2020_06 table because the order_date falls within the partition key range for that table.
INSERT INTO orders
(customer_id, order_total, order_date)
VALUES (123, 12599, '2020-06-10T11:57:06.819Z')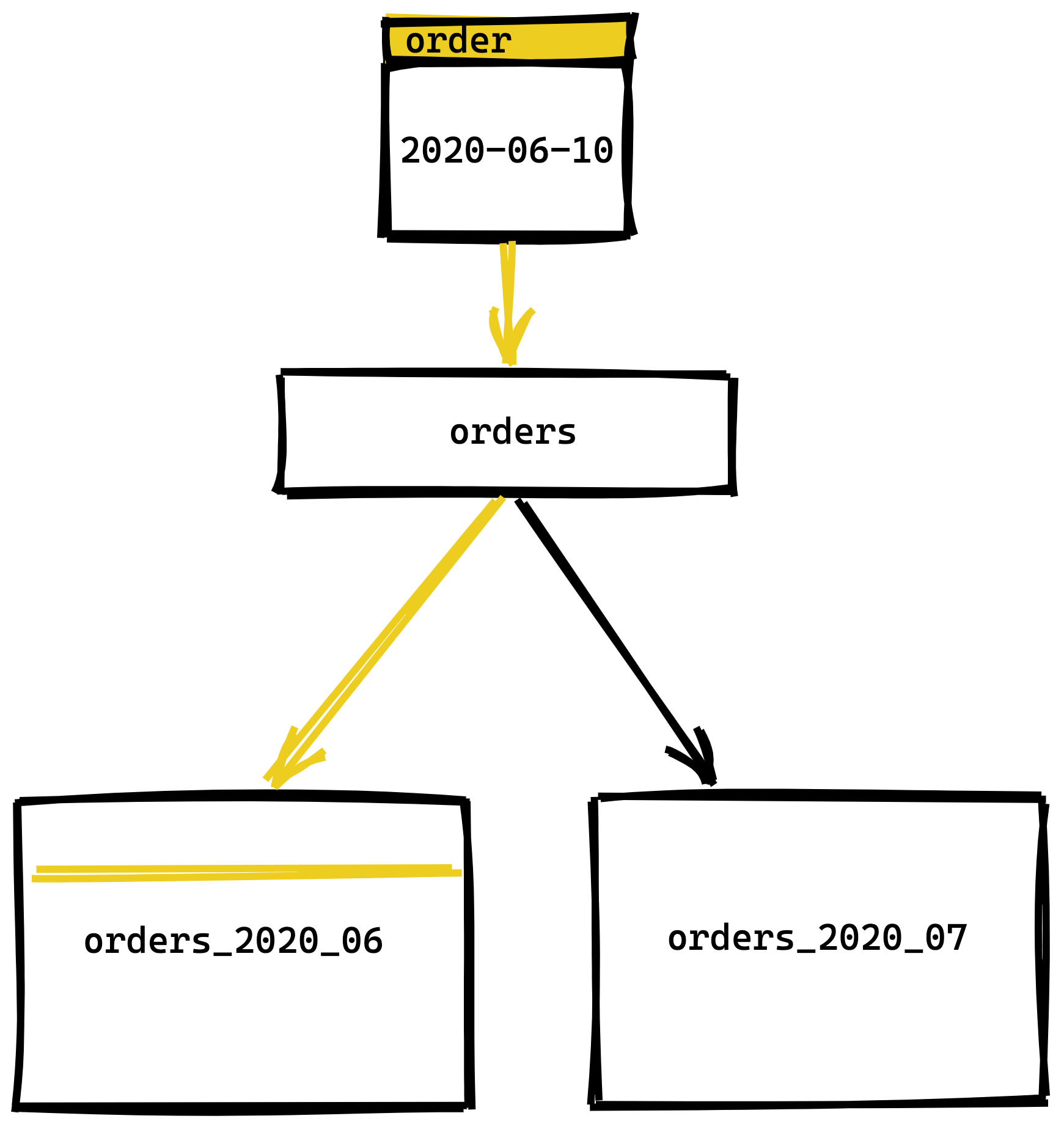
Now let's fast forward to July 2021. We've been creating new child partitions each month and we now have 13 child partitions, one for each month since we started in June 2020.
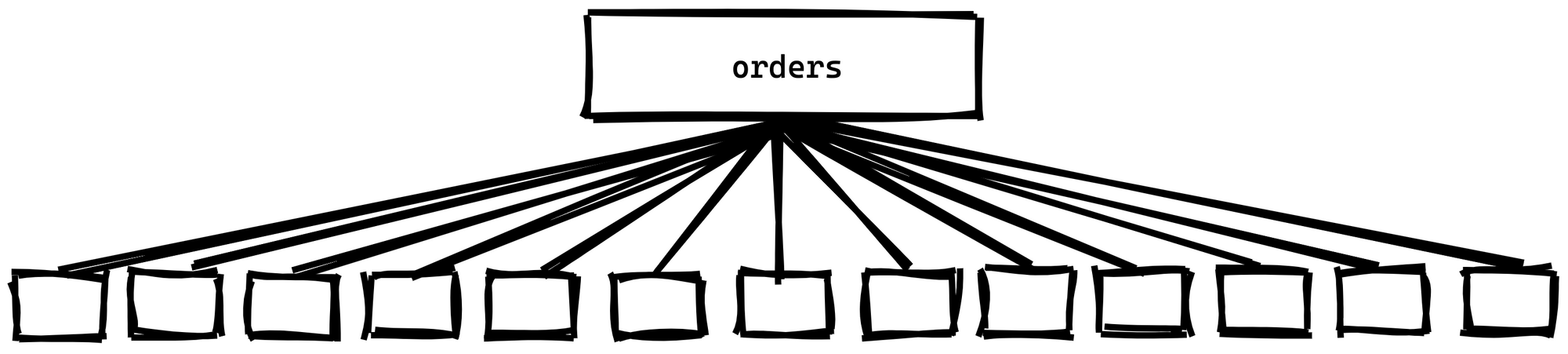
We want to archive the June 2020 data as it's no longer needed for 99% of our queries. The specific details for archiving that data will be different for every setup, so we'll gloss over that. We're just going to look at how we remove a partition table.
First we want to detach the child from the partition so that any archiving operations don't affect the queries being sent to the orders table.
ALTER TABLE orders DETACH PARTITION orders_2020_06;Next we would archive using pg_dump, COPY, or some other process specific to our setup. Then, once our data is safely archived we can drop the child table.
DROP TABLE orders_2020_06;That's it, now our orders partition contains 12 partition tables containing the last 12 months of data.
Caveats
- Postgres does not automatically create the child partition tables. Each child partition table needs to be created ahead of time.
- If you try to insert data that doesn't fit within any child partitions range you'll run into an error.
- "Declarative Partitioning" like we've discussed here was introduced in Postgres version 10. Partitioning is still possible on older versions, but it will require more manual setup.
Wrapping up
This was a very high level overview of table partitioning. There is a lot of nuance that we glossed over here. For example, we only discussed the range partitioning method. There is also a list partitioning method which allows you to list which values belong in each partition. Before you start using table partitioning I encourage you to read the official documentation to understand the finer details that we glossed over.